Counting Copyright Registrations 1870-1909
This past spring/summer, my article (coauthored with Richard Schwinn, Ph.D) entitled “An Empirical Study of 225 Years of Copyright Registrations” was published. This post is part of a series studying particular parts of my paper, and sharing in greater detail than I could there some insights.
In 1870, copyright registration activity was centralized at the Library of Congress. My previous post looked at counting registrations before 1870 when registration activity was in the individual district Courts, and basically involved counting pages of records, which generally correspond 1:1 with registrations. However, in 1870 copyright registration was centralized, along with deposit, in the Library of Congress.
With the switch in administration of copyright law effective the day the new law was signed, the transition was not necessarily clean. Many courts show registrations later in 1870 and even in 1871 (the Utah territorial court recorded them until 1879, I’m not quite sure what was going on there). However, the general public seems to have adjusted quickly to the change. The Library of Congress put out circulars explaining how to register to assist with the change (these are mostly from the Copyright Office’s internal files, where they were already collected, but I added 1870 myself, from the Warshaw Collection at the Museum of American History). However, the process of registration really was pretty similar before and after 1870, with the only real change being that of venue. Like before registration was done by depositing a title page and making out a registration to the Librarian of Congress and paying the fee – all before publication. Within ten days after publication two copies of the best edition of the work would be sent to the Librarian of Congress to “perfect” the registration.
Data Sources
One resource I found at the US Copyright Office and was able to use was the record book kept by the Librarian of Congress tallying daily entries by type. for 1875-1885. This book was pretty clearly the basis for the tallies found in the Librarian’s annual reports, and there may be additional research to be done with it in terms of daily and monthly breakdowns. For my purposes, it mostly served to prove that in fact the tallies in the Librarian’s annual reports were for calendar years, not fiscal years. Accordingly, I was able to use the Librarian’s annual reports on copyright business for yearly tallies until 1896.
One confusing detail is that the number of registrations reported for these years was actually the number of deposits made divided by two (because in most cases two deposits of a work were required (this is obvious looking at the above record book). However, clearly in many cases only single copies were deposited, so the number is likely a mild undercount. The why of this isn’t entirely clear – there isn’t any reference to single deposits being permitted in the statute or rules, to the extent they existed, although in the future single deposits would be permitted for things like contributions to periodicals. In the mid-1890s the Librarian stopped reporting the number of deposits and instead reported the number of works deposited, meaning that the numbers no longer need to be divided in half – and are no longer an undercount.
1897 is a problem year in terms of recordkeeping, at least from looking at the annual report. Only 3 months of entries are tallied and the report is clear that this is incomplete. However, in January of 1898 the Librarian transmitted a letter to Congress with the proper numbers for the 1897 calendar year. From 1898 forward the annual reports of the new Copyright Office use fiscal year instead of calendar year for their tallies, leading to the question of how much it mattered to use fiscal year or calendar year statistics. Although in theory these tallies are mostly interesting in terms of tracking large-scale shifts in registration volume, and the change shouldn’t matter that much, having more heterogeneity in the data isn’t ideal. Indeed, there was routinely a 5-10% variance between fiscal and calendar year statistics, as seen below, and using calendar year statistics as much as possible is a way to avoid that. Nonetheless, we had to use fiscal year statistics for 1898-1902 as there is no other data source for those years.
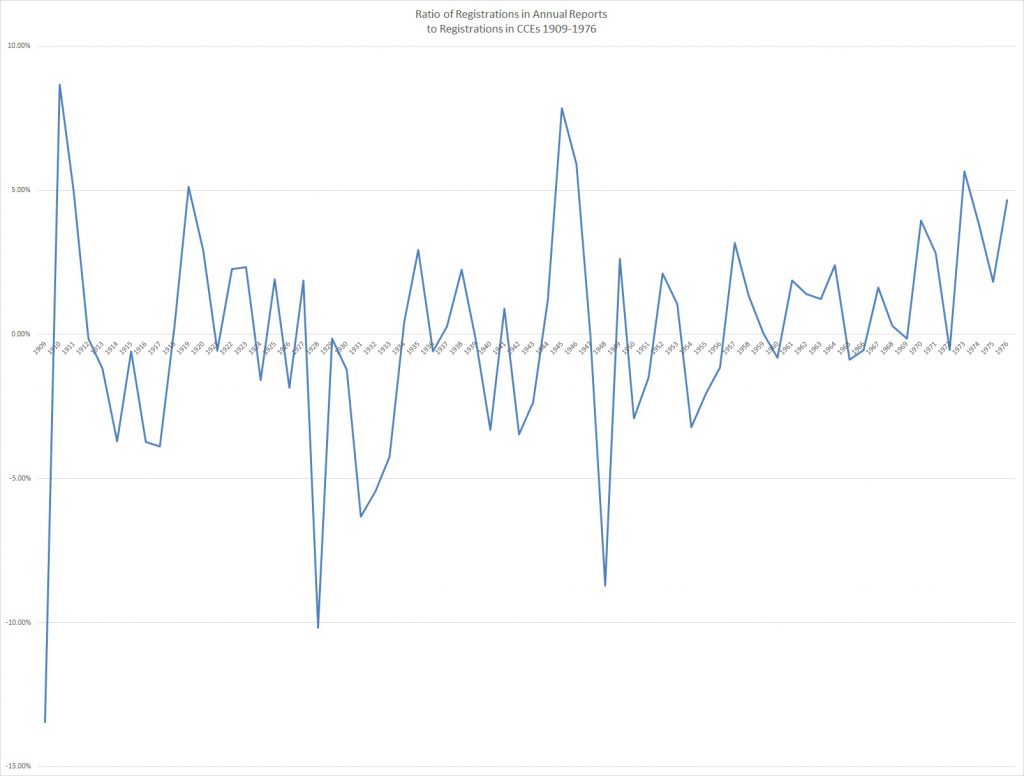
The Catalog of Copyright Entries began publication in 1891, as a biweekly catalog of copyright entries, which because of its lack of organization or information beyond lists didn’t prove particularly helpful. Starting in 1903, though, the Catalog of Copyright Entries began including statistics for the first time, and using these we were able to go back to using calendar year statistics going forward, dramatically simplifying our data process through 1909 (and indeed much later).
Ghost Books
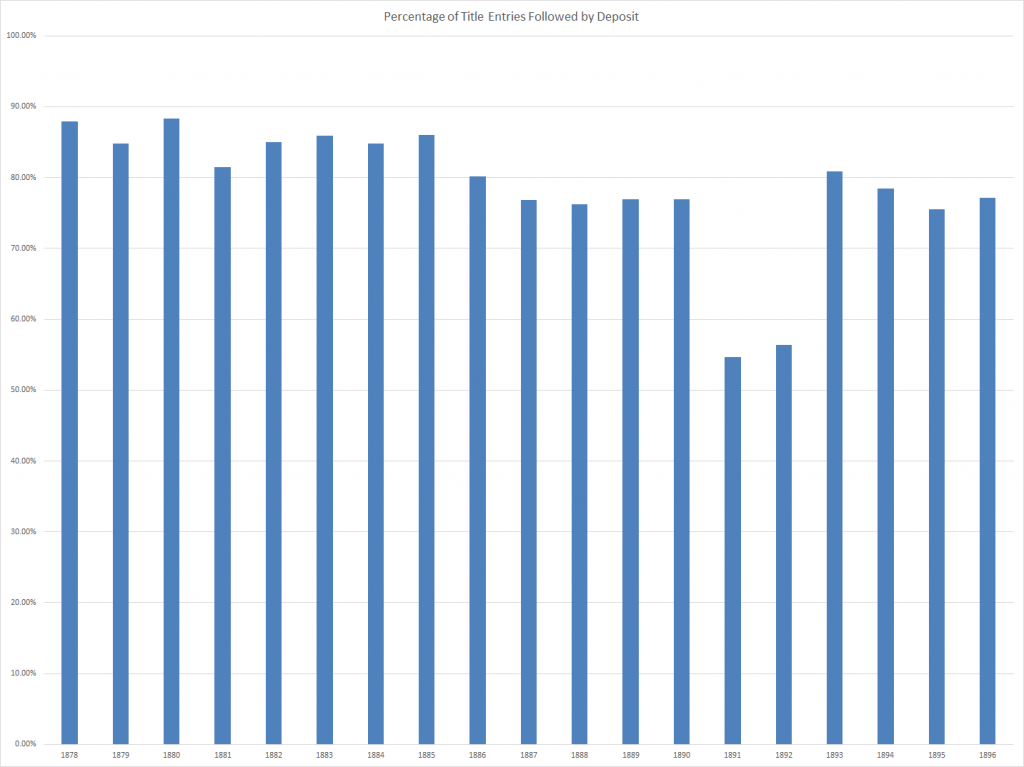
One interesting phenomenon is that of “ghost books” – works where the title was entered but the registration was not perfected by deposit. For 1878-1896 the Librarian kept records of both entries and deposits, allowing a simple calculation of percentage of registrations were perfected by deposit – and which were not. Generally speaking it seems that about 20% of works were not deposited, either through inattention or because the work was never actually completed.
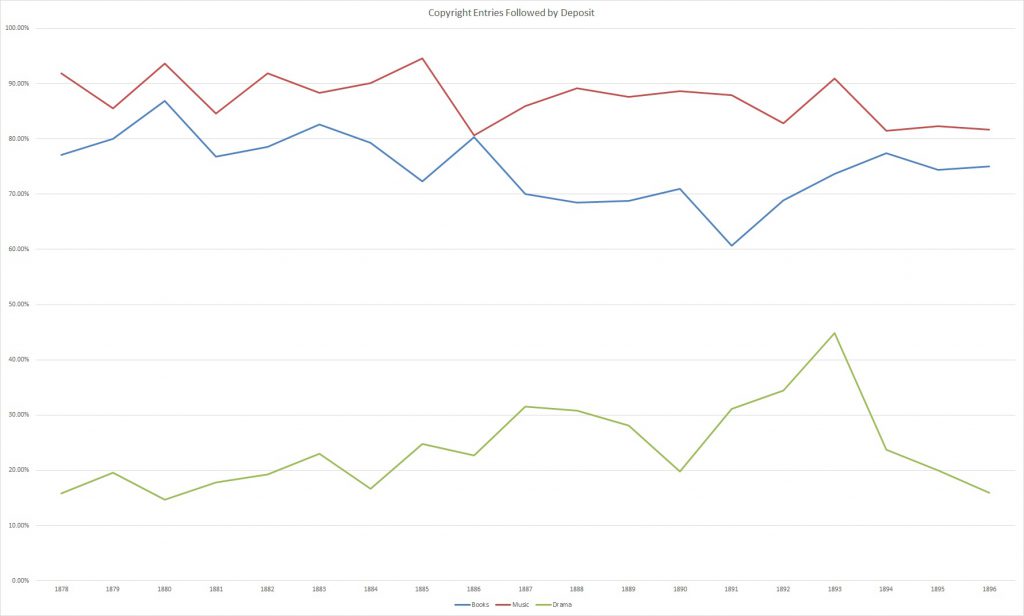
The ledgers break down by type of work as well, showing that music was perfected at a higher rate than books, although the two are pretty similar. Drama on the other hand had an abysmal rate of deposit, and it’s not clear why. Many dramas were unpublished and it’s possible only one copy was being deposited (indeed, the above record book shows many days with only a single deposit). It’s also possible that for unpublished works nothing was ever deposited, since the point was only to claim copyright without suing to enforce it.
The Data
The purpose of this post has been to give a brief discussion of our data for this period. Much of the data from this project is available on GitHub, -including our R code as well. In addition, I’ve created an Excel File with the more detailed data on just the 1870-1909 era. This is a little different looking than our main data file – before 1909 a number of different classification schema were used, and for the main data file on Github I harmonized pre-1909 data to post-1909 forms. I hope people find this data helpful, and there’s still a few more posts to come from this article.




